Partition and Min-Heap -- leetcode215
题干
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
题解1——快排变式-partition
因为快速排序每次会把一个数字放在数组正确的位置,然后递归处理左区间和右区间。
利用此特性,如果我们要找数组中的第k大,假设数组长度为n = len(nums),则等价于找到快排得到的-下标为n - k的元素,返回对应元素即可。
共有两种写法,上面的写法AC了,但是下面的写法在最后一个用例TLE了,最后一个用例是50000个元素,且很多重复的1。由以往知识知,当数组呈现有序状态时,快排的时间复杂度会变为最坏的情况 \(O(n^2)\),那为什么上面的这种写法也是快排分治的思想却能通过这题呢?让我们回到代码:
对于50,000个1+零散的几个数的测试用例,上面这种写法
- 若pivot > 1,例如pivot = 2,则这种写法会先跳过全部的1,然后把2放在正确的位置,然后对左边的1区间每次减半处理
- 若pivot = 1,则这种写法因为left和right每次各往中间移1位,所以最终交汇点会接近数组mid,这等价于每次子问题规模减半
时间复杂度公式为:\(S = 1 + 2 + 4 + \cdots + \frac{n}{2} + n = \sum_{k=0}^{\log_2{n}} 2^k = n - 1 = O(n)\)
# AC
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
l, r = 0, len(nums) - 1
target = len(nums) - k
while l <= r:
index = self.partition(nums, l, r)
if index == target:
return nums[index]
elif index > target:
r = index - 1
else:
l = index + 1
return nums[l]
def partition(self, nums: List[int], left: int, right: int) -> int:
pivot_index = left + random.randint(0, right - left)
self.swap(nums, left, pivot_index)
pivot = nums[left]
le = left + 1
ge = right
while True:
while le <= ge and nums[le] < pivot:
le += 1
while le <= ge and nums[ge] > pivot:
ge -= 1
if le >= ge:
break
self.swap(nums, le, ge)
le += 1
ge -= 1
self.swap(nums, left, ge)
return ge
def swap(self, nums: List[int], index1: int, index2: int):
nums[index1], nums[index2] = nums[index2], nums[index1]
# TLE
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
l, r = 0, len(nums) - 1
target = len(nums) - k
while l < r:
index = self.partition(nums, l, r)
if index == target:
return nums[index]
elif index > target:
r = index - 1
else:
l = index + 1
return nums[l]
def partition(self, nums: List[int], left: int, right: int) -> int:
low, high = left + 1, right
temp = random.randint(low, right)
self.swap(nums, left, temp)
while low <= high:
while low <= high and nums[low] <= nums[left]:
low = low + 1
while low <= high and nums[high] >= nums[left]:
high = high - 1
if low > high:
break
self.swap(nums, low, high)
self.swap(nums, left, high)
return high
def swap(self, nums: List[int], index1: int, index2: int):
nums[index1], nums[index2] = nums[index2], nums[index1]
题解2——小顶堆/优先队列
\(Topk\) 的问题一般都要会用到堆,如果找第k大,通常是建大小为k的小顶堆,依次遍历数组,如果大于堆顶元素,则将堆顶pop后,将该元素push,然后heapify调整堆结构,每次heapify时间复杂度为 \(log k\),共n次
总时间复杂度为:\(O(n \log k)\)。
事实上,可以先用前k个元素建堆,如果原地建堆,复杂度为 \(O(k)\),然后共 \((n - k)\)次 heapify
总时间复杂度为\(O(k)+(n - k) * O( \log k)\)
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int,vector<int>,greater<int>> pq;
for(int i = 0; i < k; i++) pq.push(nums[i]);
// int count = nums.size() - k + 1;
for(int i = k; i < nums.size(); i++){
if(nums[i] >= pq.top()){
pq.pop();
pq.push(nums[i]);
}
}
return pq.top();
}
};
python的heap写法留个坑以后再补,今天先下班了- -!
补档!可以分别测试前k个元素原地建堆和依次读取前k个建堆,如果k较大时有: \(O(k) < O(k \log k)\)
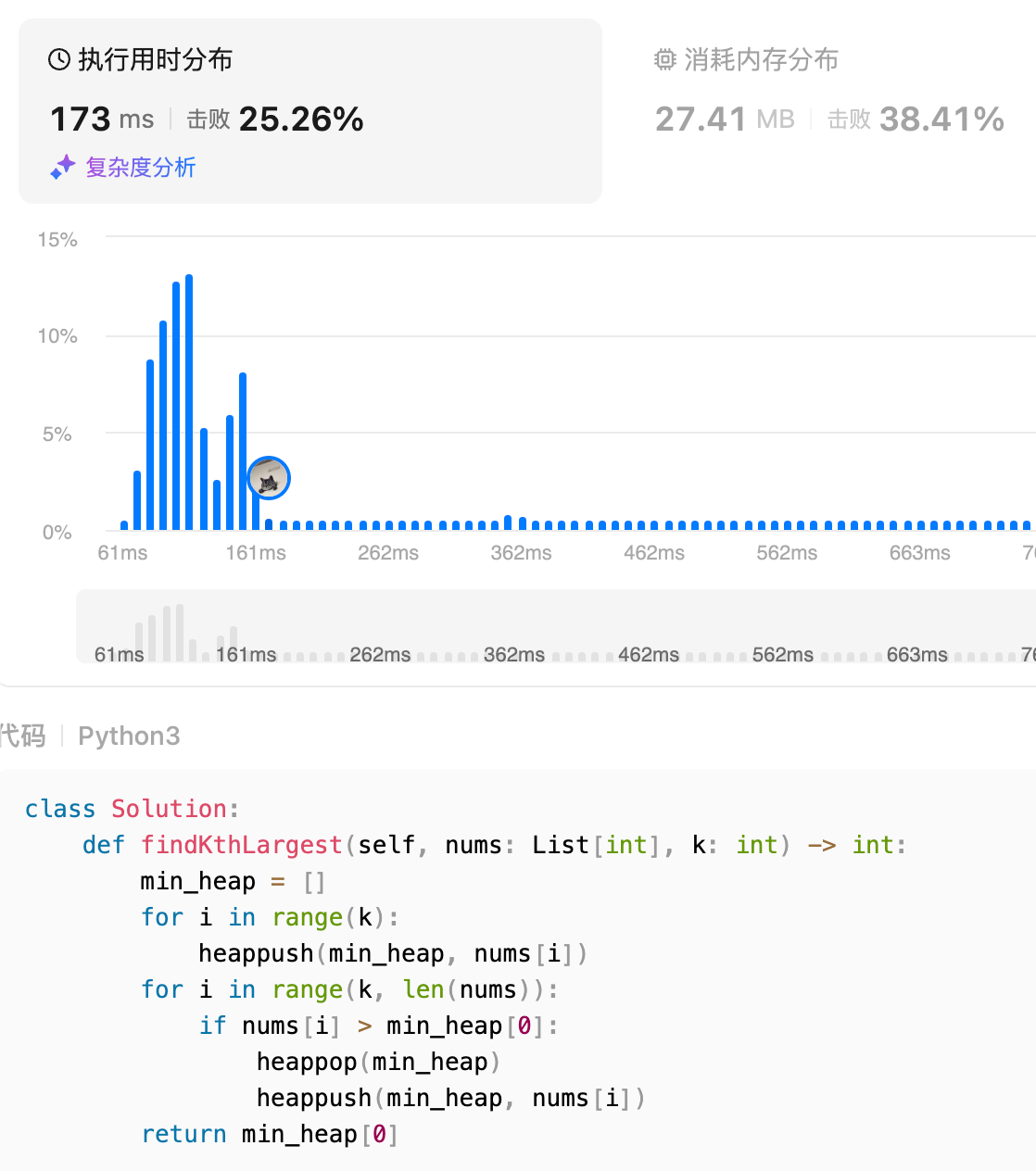
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
# 使用前k个元素创建一个小顶堆
min_heap = nums[:k]
heapq.heapify(min_heap)
# min_heap = []
# for i in range(k):
# heappush(min_heap, nums[i])
for i in range(k, len(nums)):
if nums[i] > min_heap[0]:
heappop(min_heap)
heappush(min_heap, nums[i])
return min_heap[0]
前k个元素原地建堆
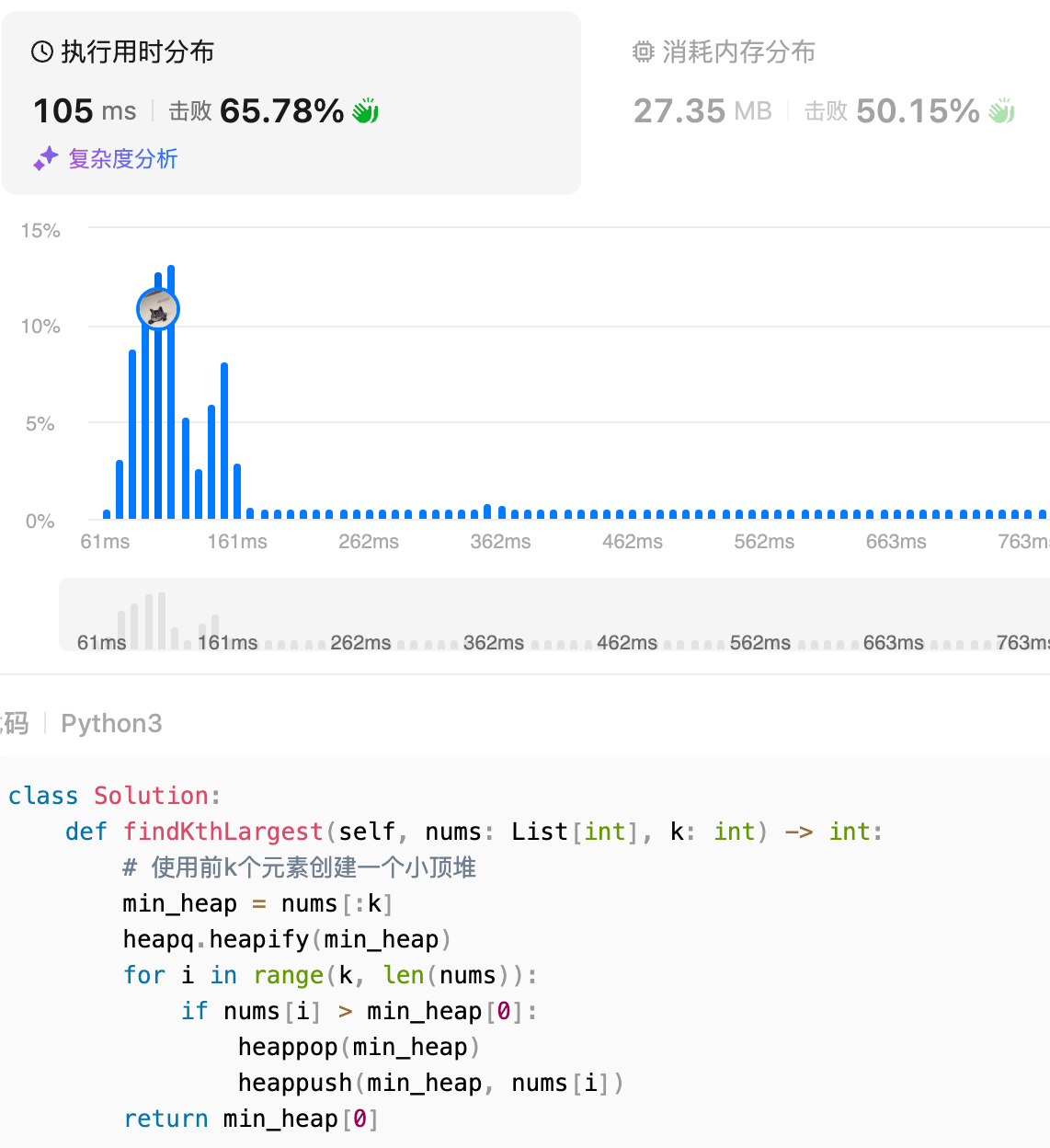
依次建堆